孫冰 邁向海量流數據處理的服務化新時代

在當今數據爆炸的時代,流數據已成為企業洞察實時業務、優化決策的關鍵資源。從物聯網傳感器、在線交易日志到社交媒體動態,海量、高速、持續的數據流對傳統數據處理架構提出了嚴峻挑戰。在此背景下,數據處理服務化(Data Processing as a Service, DPaaS)作為一種創新的范式應運而生,旨在將復雜的流數據處理能力封裝成標準化、可彈性伸縮的服務,從而降低使用門檻,提升開發與運維效率。
孫冰及其團隊在該領域的探索與實踐,為我們揭示了海量流數據處理服務化的核心路徑。其核心理念在于解耦與抽象:將數據接入、實時計算、狀態管理、結果輸出等復雜環節從具體的業務邏輯中剝離,通過統一的API、配置化管道以及聲明式的處理規則,使開發人員能夠像調用普通服務一樣,專注于業務價值的實現,而無需深陷底層框架與集群管理的技術細節。
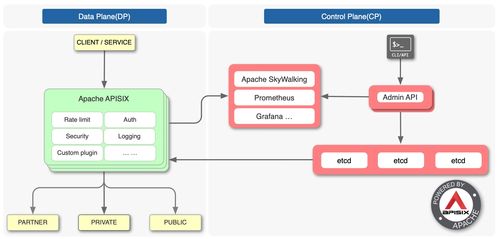
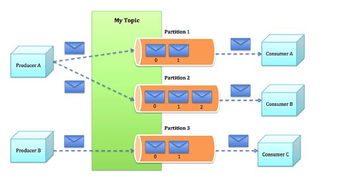
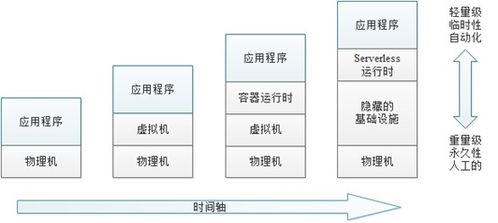
實現這一愿景,需要構筑堅實的技術底座。是高性能、高可用的流計算引擎,如經過深度優化的Apache Flink或Spark Streaming,它們能夠保障在每秒百萬甚至千萬級事件處理下的低延遲與強一致性。是服務化框架的設計,包括多租戶隔離、彈性資源調度、動態擴縮容以及完善的監控告警體系,確保服務穩定、成本可控。是生態的集成能力,能夠無縫對接各類消息隊列(如Kafka、Pulsar)、存儲系統(如HDFS、S3、數據庫)以及下游的分析與應用服務。
孫冰強調,服務化的成功不僅在于技術,更在于對用戶痛點的深刻理解與對服務體驗的極致追求。一個優秀的數據處理服務應當具備:
- 簡易性:提供直觀的圖形化界面或簡潔的SDK,支持通過拖拽或少量代碼即可構建復雜的流處理任務。
- 可靠性:保證數據處理的精確一次(Exactly-Once)語義,具備完善的故障恢復與數據回溯機制。
- 可觀測性:提供全鏈路的數據血緣、處理延遲、資源消耗等指標的實時監控與可視化,問題可追溯、可診斷。
- 智能化:集成機器學習能力,實現異常檢測、智能預警等,讓數據處理服務更具洞察力。
隨著邊緣計算與5G的普及,流數據的源頭將更加分散,實時性要求也將更高。數據處理服務化將向更邊緣、更智能、更自治的方向演進。孫冰認為,構建一個開放、標準、云原生的流數據服務生態,讓數據如水一般在其間自由、高效、可靠地流動并產生價值,是推動各行各業數字化轉型的重要基石。從技術攻堅到服務賦能,海量流數據處理正迎來一個更加普惠和高效的新時代。
如若轉載,請注明出處:http://m.xg7b.com.cn/product/51.html
更新時間:2026-02-14 12:00:17